Ateliers R Trucs et Astuces
Introduction à la modélisation statistique et aux simulations de données
5/12/24
Biais, précision et variance d’échantillonage
Code
iter = 100
n = c(5:200)
b0 = 100
b1 = 10
sigma = 10
counter = 0 # compteur à incrémenter de 1 à chaque itération
out = matrix(NA, nrow = iter*length(n), ncol = 7)
colnames(out) = c("iter", # numéro de simulation
"n", # nombre de mesures par groupe
"b1_sim", # différence simulée
"b1_est", # différence estimée
"p", # p-value
"diff_est", # erreur de mesure (est - sim)
"perc_diff" # % erreur (est - sim) / sim * 100
)
# Barre de progression
pb <- progress_bar$new(
format = " downloading [:bar] :percent eta: :eta",
total = nrow(out), clear = FALSE, width= 60)
set.seed(42)
for (i in 1:iter) {
for (reps in 1:length(n)) {
pb$tick()
Sys.sleep(1 / nrow(out))
counter = counter + 1
# Génération du jeu de données simulées
dfsim = data.frame(Id = 1:(n[reps]*2),
groupe = c(rep("1", n[reps]),
rep("2", n[reps])))
dfsim$xi = ifelse(dfsim$groupe == "1", 0, 1)
dfsim = dfsim %>%
mutate(y = rnorm(n(), b0 + b1 * xi, sigma))
# modèle statistique
lm.sim = lm(y ~ groupe, dfsim)
b1_est = as.numeric(coef(lm.sim)[2]) # valeur de b1 estimée
p = p_value(lm.sim)$p[2] # p-value pour b1
diff_est = b1_est - b1
perc_diff = diff_est / b1 * 100
# stockage des données à la ième ligne de la matrice 'out'
out[counter, 1] = i # numéro de simulation
out[counter, 2] = n[reps] # nombre de mesures par groupe
out[counter, 3] = b1 # différence simulée
out[counter, 4] = b1_est # différence estimée
out[counter, 5] = p # p-value
out[counter, 6] = diff_est # erreur de mesure (est - sim)
out[counter, 7] = perc_diff # % erreur (est - sim) / sim * 100
}
}
out %>%
data.frame() %>%
ggplot(aes(x = n, y = b1_est, fill = n)) +
geom_point(alpha = .9, size = 2, shape = 21, color = "black") +
geom_hline(yintercept = b1, linetype = "dashed", size = 1.5) +
scale_fill_viridis(option = "H", direction = -1) +
xlab("Taille d'echantillon par groupe") +
ylab("b1")
Visualisation de l’erreur de type M & S
Code
out = as.data.frame(out)
out = out %>%
mutate(S = ifelse(b1_est < 0, 1, 0),
M = ifelse(abs(b1_est - b1_sim) / b1_sim > .2,
1, 0))
p1 = out %>%
ggplot(aes(x = n, y = b1_est, fill = factor(M))) +
geom_point(alpha = .9, size = 2, shape = 21) +
geom_hline(yintercept = b1, linetype = "dashed", size = 1.5) +
scale_fill_manual(values = c("white", "red")) +
xlab("Taille d'echantillon par groupe") +
ylab("b1") +
theme(legend.position = "none") +
labs(title = "Erreur de type M",
subtitle = "Estimés > 20 % d'erreur")
p2 = out %>%
ggplot(aes(x = n, y = b1_est, fill = factor(S))) +
geom_point(alpha = .9, size = 2, shape = 21) +
geom_hline(yintercept = b1, linetype = "dashed", size = 1.5) +
scale_fill_manual(values = c("white", "red")) +
xlab("Taille d'echantillon par groupe") +
ylab("b1") +
theme(legend.position = "none") +
labs(title = "Erreur de type S")
p1 + p2
Taille du bec x taille des ailes chez les manchots

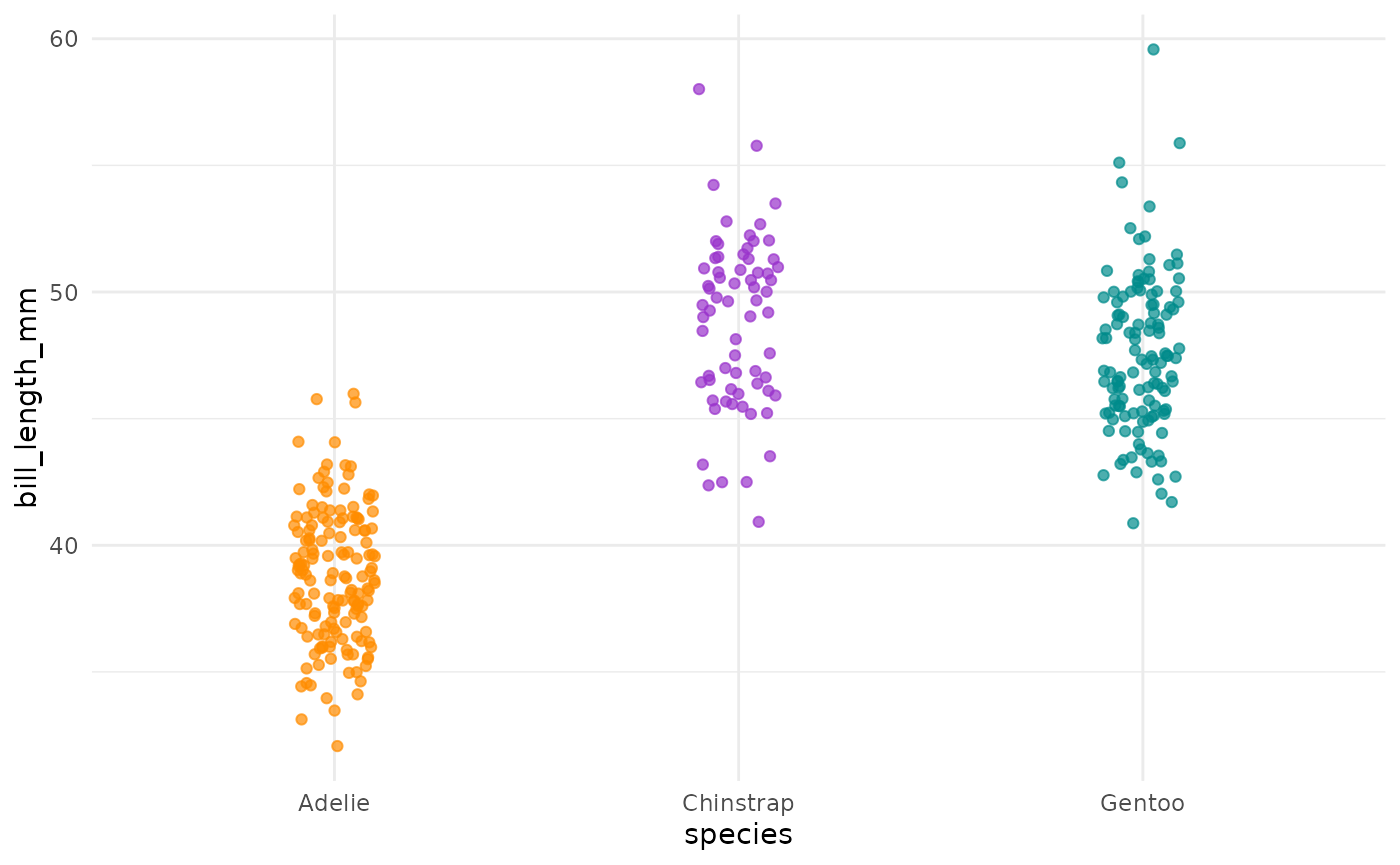{kind=link}
Coder le modèle

Inspecter le modèle
Code

Inspecter le modèle
Code

BONUS : Test d’équivalence
- Région d’équivalence = +/- 5 unités
- p(Equiv) > 0.05 -> l’effet n’est pas dans la région d’équivalence

BONUS : Analyse de puissance
Code
out %>%
mutate(sig = case_when(p < 0.05 ~ 1, p >= 0.05 ~ 0)) %>%
group_by(n) %>%
summarise(sig.prop = sum(sig)/n() * 100) %>%
ggplot(aes(x = n, y = sig.prop, fill = n)) +
geom_line() +
geom_point(alpha = .9, size = 3, shape = 21, color = "black") +
geom_hline(aes(yintercept=80),linetype="dashed") +
scale_fill_viridis(option = "H", direction = -1) +
xlab("Taille d'echantillon par groupe") +
ylab("Puissance statistique")
